This is Part 3 of my offline JavaScript series and it covers intermittently offline web apps. The vast majority of web apps are built on the false assumption that the internet will always be available. Yes, the internet is available the vast majority of the time, and most of us rarely encounter issues. However when, not if but when, the internet fails most web apps simply crash and burn in fairly spectacular fashion. I suggest a different approach that there are many, many common use cases that can benefit from offline capabilities in both consumer and professional apps.
As discussed in Part 1, intermittently offline web apps are designed to gracefully handle the occasional, temporary internet connection hiccup. The goals of an intermittent offline app are to make the offline capabilities are lightweight, invisible to the user, and allow the user to seamless pass thru a temporary loss of data connectivity.
The good news, as discussed in Part 2, is you can use a variety of libraries and APIs to solve many of the challenges related to partial offline including detecting whether or not you have an internet connection, and handling of http requests while offline.
How do I decide if I need intermittent offline capabilities?
If you answer ‘yes’ to the following question then you need to consider adding offline capabilities:
Does the app have any critical functionality that could fail if the internet temporarily goes down?
Critical functionality means functionality that’s important to your core business. And to be realistic I’m not talking about building fully armored applications that take every possible contingency into account. That’s just not feasible for the vast majority of non-military-grade applications. Some of the most common use cases are filling in forms and requesting data. And, temporary interruptions can be vary anywhere from a few seconds to a few minutes or longer, and they can happen once or multiple times.
If your application can’t handle this and it needs to then making changes to allow it to be offline can make a big difference to the user. It’s almost as if web development should have it’s own version of “Do no harm” or something like “we can do our best to make users lives easier.” You might be surprised that some very simple and common use cases can benefit from being offline enabled such as filling in form data, or reading an online article.
Filling in form data. This has probably happened to everyone who uses the internet and it applies to both retail/consumer and commercial applications. You spend a while filling out a detailed web form only to have the submit fail and destroy all your hard work because of a temporary interruption in the internet connection or something simply went wrong between the app and the web server.
If our form data was offline-enabled we could store the form data in LocalStorage before attempting to send the data to the server. We could also temporarily prevent the web form from submitting and notify the user there is no internet connection.
Reading an online article. In this scenario you are reading an article while waiting for a train. Once you get on the train you know the internet will be marginal. You accidentally click on navigation link while scrolling down and the new page fails to load. This effectively ruins your browsing experience because the new page failed to load and you can’t go back to the previous page because it wasn’t cached..
There are a number of different ways to protect this type of application. The easiest way is to block any page load requests until the internet is restored. You can also take advantage of the built-in browser cache to store HTML, CSS, images and JavaScript.
Show me an example workflow?
The most basic workflow takes into consideration the following questions. How these questions get answered depends on your requirements.
- Do you allow users to restart apps while offline?
- Do you simply block all HTTP requests and lock down the app?
- Do you queue HTTP requests and their data?
- Do you pre-cache certain data?
- How will you detect if the app is online or offline?
Here is an example coding pattern for the most basic intermittent offline workflow:
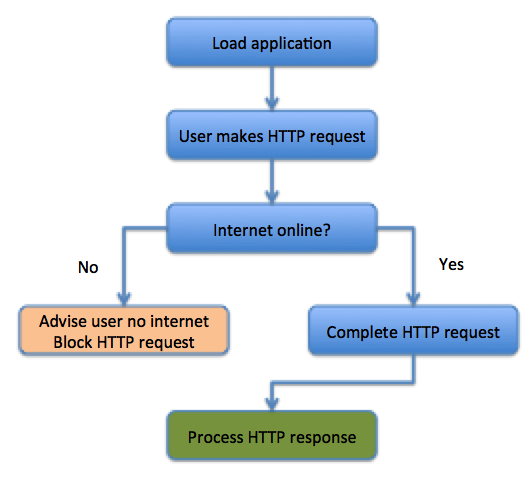
What about Offline/Online detection?
If you have no control over what browsers your customers choose, then my recommendation is to use a pre-built library such as Offline.js to check if the internet connection is up or down. It’s not perfect but it’s the best choice out there as of the writing of this post.
Don’t only rely on the window.navigator.online property. It has too many inconsistencies and it is only marginally reliable if the general public is using your app.
What about caching?
There are several built-in browser caching mechanisms that can help your app get past the occasionally internet hiccup. When your app goes offline, you’ll have to rely on local, in-browser resources to keep things going:
- Browser Caching
- LocalStorage
- IndexedDB
As mentioned above, browser caching can be a very efficient way to store HTML, JavaScript, images and CSS. Depending on how you set up your web server, this caching takes place automatically in the users browser and can represent a huge performance gain in eliminating HTTP round trips. I’m not going to talk much about this because there are a ton of great online resources already out there.
Using LocalStorage involves writing JavaScript code if you want to temporarily store HTTP requests. It’s limited to String-based data, so if you are using Objects or binary data you’ll have to serialize the data when you write it to LocalStorage and deserialize when you read it out. LocalStorage also almost always has a limit in terms of how much storage is available. 5MB is the commonly accepted limit.
IndexedDB, on the other hand, stores a wide variety of data types and can store significantly more than 5MB. While in theory the amount of storage space available to IndexedDB is unlimited, practical application of it on a mobile device limits you to around 50MB – 100MB. Your mileage may vary depending on available device memory, the current memory footprint of the browser and the phone’s operating system.
IndexedDB can work natively with types String, Object, Array, Blob, ArrayBuffer, Uint8Array and File. This offers a huge pre- and post-processing savings if you simply are able to pass data directly into IndexedDB.
There are also a number of abstraction libraries that wrap LocalStorage and IndexedDB such as Mozilla’s localForage. These types of libraries are great if you have requirements to store 5MBs of data or less. If your app is running a browser that doesn’t support IndexedDB or WebSQL (e.g. Safari), and you need more than 5MBs of space then you’ll have problems. One potential advantage of some of these libraries is that some of them provide their own internal algorithms for serializing and deserializing data. If working directly with algorithms isn’t your thing, then a library like this can be a huge benefit.
Can you show me some code?
Yes! Here is a very simple example of how to implement basic offline detection into your apps. It’s easiest to try it in Firefox since you can quickly toggle it online/offline using the File > Work Offline option.
The code is available at: https://jsfiddle.net/agup/1yxj5mzp/. You’ll notice two things when you go offline. First is that jsfiddle, itself, will detect you are offline in addition to the web app code. When you go to click the Get Data button while offline, the code sample should detect you are offline and fire off a JavaScript alert.
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="UTF-8">
<title>Simple Offline Demo</title>
</head>
<body>
<div id="status">Status is:</div>
<button onclick="getData()">Get Data</button>
<!-- This is our Offline detection library -->
<script src="https://github.hubspot.com/offline/offline.min.js"></script>
<script>
// Set our options for the Offline detection library
Offline.options = {
checkOnLoad: true,
checks: {
image: {
url: function() {
return 'https://esri.github.io/offline-editor-js/tiny-image.png?_='
+ (Math.floor(Math.random() * 1000000000));
}
},
active: 'image'
}
}
Offline.on('up', internetUp);
Offline.on('down',internetDown);
var statusDiv = document.getElementById("status");
statusDiv.innerHTML = "Status is: " + Offline.state;
function getData() {
// See if internet is up or down
Offline.check();
switch (Offline.state) {
case "up":
// If the internet is up go ahead and retrieve data.
getFeed(function(success,response){
if(success){
alert(response);
}
})
break;
case "down":
alert("DOWN");
break;
}
}
function getFeed(callback) {
var req = new XMLHttpRequest();
req.open("GET",
"https://tmservices1.esri.com/arcgis/rest/services/LiveFeeds/Earthquakes/MapServer?f=pjson");
req.onload = function() {
if (req.status === 200 && req.responseText !== "") {
callback(true,req.responseText);
} else {
console.log("Attempt to retrieve feed failed.");
callback(false,null);
}
};
req.send(null);
}
function internetUp(){
console.log("Internet is up.");
statusDiv.innerHTML = "Status is: up";
}
function internetDown(){
console.log("Internet is down.");
statusDiv.innerHTML = "Status is: down";
}
</script>
</body>
</html>
Are there any examples of real-life offline apps or libraries?
The github repository offline-editor-js is a full-fledged set of libraries for taking maps and mapping data offline and it’s being used in commercial mapping applications around the world. It includes a variety of sample applications that demonstrate how applications can work in either intermittently or fully offline mode.
Wrap-up
Hopefully you have seen that common use cases can significantly benefit from having basic offline capabilities. Modern browsers have advanced to the point where it’s fairly easy to build web apps that can survive intermittent interruptions in the internet. Taking advantage of these capabilities can offer a huge benefit to your end users.
Resources
Optimizing content efficiency – HTTP caching
Offline-editor-js – Offline mapping library